Longitudinal Model
Contents
- Longitudinal Model: From measurements at the first visit and the time till the last visit we predict disease progression at the last visit
- 1 Data loading, preperation and cleaning
- 2 Base Logistic Regression Model
- 3 Advanced Model Testing with Cross Validation score reporting and CV parameter optimization within training fold
- 3.1 Parameter Optimisation and Cross Validation
- 3.2 Model Performance and Area Under The Receiver Operating Characteristic Curve
- The actual Parameter Optimisation and 4-fold CV code
- 3.4 Model testing of KNN, Logistic Regression, Decision Tree Classifier, Random Forest, Gradient Boosting, XGBoost, MLP and Light-GBM for predicing Normal Baseline patients progressing to MCI/AD at last visit.
- 3.4 Model testing of KNN, Logistic Regression, Decision Tree Classifier, Random Forest, Gradient Boosting, XGBoost, MLP and Light-GBM for predicing MCI Baseline patients progressing to AD at last visit.
- 4 Summary
Longitudinal Model: From measurements at the first visit and the time till the last visit we predict disease progression at the last visit
Disease progression is defined as worsening of diagnosis on the last visit compared to the the baseline diagnosis.
1 Data loading, preperation and cleaning
| RID | PTID | VISCODE | SITE | COLPROT | ORIGPROT | EXAMDATE | DX_bl | AGE | PTGENDER | PTEDUCAT | PTETHCAT | PTRACCAT | PTMARRY | APOE4 | FDG | PIB | AV45 | ABETA | TAU | PTAU | CDRSB | ADAS11 | ADAS13 | ADASQ4 | MMSE | RAVLT_immediate | RAVLT_learning | RAVLT_forgetting | RAVLT_perc_forgetting | LDELTOTAL | DIGITSCOR | TRABSCOR | FAQ | MOCA | EcogPtMem | EcogPtLang | EcogPtVisspat | EcogPtPlan | EcogPtOrgan | EcogPtDivatt | EcogPtTotal | EcogSPMem | EcogSPLang | EcogSPVisspat | EcogSPPlan | EcogSPOrgan | EcogSPDivatt | EcogSPTotal | FLDSTRENG | FSVERSION | IMAGEUID | Ventricles | Hippocampus | WholeBrain | Entorhinal | Fusiform | MidTemp | ICV | DX | mPACCdigit | mPACCtrailsB | EXAMDATE_bl | CDRSB_bl | ADAS11_bl | ADAS13_bl | ADASQ4_bl | MMSE_bl | RAVLT_immediate_bl | RAVLT_learning_bl | RAVLT_forgetting_bl | RAVLT_perc_forgetting_bl | LDELTOTAL_BL | DIGITSCOR_bl | TRABSCOR_bl | FAQ_bl | mPACCdigit_bl | mPACCtrailsB_bl | FLDSTRENG_bl | FSVERSION_bl | Ventricles_bl | Hippocampus_bl | WholeBrain_bl | Entorhinal_bl | Fusiform_bl | MidTemp_bl | ICV_bl | MOCA_bl | EcogPtMem_bl | EcogPtLang_bl | EcogPtVisspat_bl | EcogPtPlan_bl | EcogPtOrgan_bl | EcogPtDivatt_bl | EcogPtTotal_bl | EcogSPMem_bl | EcogSPLang_bl | EcogSPVisspat_bl | EcogSPPlan_bl | EcogSPOrgan_bl | EcogSPDivatt_bl | EcogSPTotal_bl | ABETA_bl | TAU_bl | PTAU_bl | FDG_bl | PIB_bl | AV45_bl | Years_bl | Month_bl | Month | M | update_stamp | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 011_S_0002 | bl | 11 | ADNI1 | ADNI1 | 2005-09-08 | CN | 74.3 | Male | 16 | Not Hisp/Latino | White | Married | 0.0 | 1.36665 | NaN | NaN | NaN | NaN | NaN | 0.0 | 10.67 | 18.67 | 5.0 | 28.0 | 44.0 | 4.0 | 6.0 | 54.5455 | 10.0 | 34.0 | 112.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | Cross-Sectional FreeSurfer (FreeSurfer Version... | 35475.0 | 118233.0 | 8336.0 | 1229740.0 | 4177.0 | 16559.0 | 27936.0 | 1984660.0 | CN | -4.35795 | -4.15975 | 2005-09-08 | 0.0 | 10.67 | 18.67 | 5.0 | 28 | 44.0 | 4.0 | 6.0 | 54.5455 | 10.0 | 34.0 | 112.0 | 0.0 | -4.35795 | -4.15975 | NaN | Cross-Sectional FreeSurfer (FreeSurfer Version... | 118233.0 | 8336.0 | 1229740.0 | 4177.0 | 16559.0 | 27936.0 | 1984660.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.36665 | NaN | NaN | 0.000000 | 0.00000 | 0 | 0 | 2018-11-08 22:51:22.0 |
| 1 | 3 | 011_S_0003 | bl | 11 | ADNI1 | ADNI1 | 2005-09-12 | AD | 81.3 | Male | 18 | Not Hisp/Latino | White | Married | 1.0 | 1.08355 | NaN | NaN | 741.5 | 239.7 | 22.83 | 4.5 | 22.00 | 31.00 | 8.0 | 20.0 | 22.0 | 1.0 | 4.0 | 100.0000 | 2.0 | 25.0 | 148.0 | 10.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | Cross-Sectional FreeSurfer (FreeSurfer Version... | 32237.0 | 84599.0 | 5319.0 | 1129830.0 | 1791.0 | 15506.0 | 18422.0 | 1920690.0 | Dementia | -16.58450 | -16.16580 | 2005-09-12 | 4.5 | 22.00 | 31.00 | 8.0 | 20 | 22.0 | 1.0 | 4.0 | 100.0000 | 2.0 | 25.0 | 148.0 | 10.0 | -16.58450 | -16.16580 | NaN | Cross-Sectional FreeSurfer (FreeSurfer Version... | 84599.0 | 5319.0 | 1129830.0 | 1791.0 | 15506.0 | 18422.0 | 1920690.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 741.5 | 239.7 | 22.83 | 1.08355 | NaN | NaN | 0.000000 | 0.00000 | 0 | 0 | 2018-11-08 22:51:22.0 |
| 2 | 3 | 011_S_0003 | m06 | 11 | ADNI1 | ADNI1 | 2006-03-13 | AD | 81.3 | Male | 18 | Not Hisp/Latino | White | Married | 1.0 | 1.05803 | NaN | NaN | NaN | NaN | NaN | 6.0 | 19.00 | 30.00 | 10.0 | 24.0 | 19.0 | 2.0 | 6.0 | 100.0000 | NaN | 19.0 | 135.0 | 12.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | Cross-Sectional FreeSurfer (FreeSurfer Version... | 31863.0 | 88580.0 | 5446.0 | 1100060.0 | 2427.0 | 14400.0 | 16972.0 | 1906430.0 | Dementia | -15.02030 | -13.38660 | 2005-09-12 | 4.5 | 22.00 | 31.00 | 8.0 | 20 | 22.0 | 1.0 | 4.0 | 100.0000 | 2.0 | 25.0 | 148.0 | 10.0 | -16.58450 | -16.16580 | NaN | Cross-Sectional FreeSurfer (FreeSurfer Version... | 84599.0 | 5319.0 | 1129830.0 | 1791.0 | 15506.0 | 18422.0 | 1920690.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 741.5 | 239.7 | 22.83 | 1.08355 | NaN | NaN | 0.498289 | 5.96721 | 6 | 6 | 2018-11-08 22:51:22.0 |
We are keeping only the last visit measurement since it contains all the measurements of the patient at the last visit plus baseline information.
Before we had 5059 rows.
After we had 819 rows.
When we stratify in groups based on the diagnosis of the first visit (left graph), we observe that:
- People with AD at baseline only stayed 2.5 year at the most in our data set.
- For Normal and MCI patients there were less obvious differences.
When we stratify in groups based on the diagnosis of the last visit (right graph), we observe that:
- All groups of diagnosis at the last visit have their last visits at similar times. No obvious difference between Dementia/Alzheimer and MCI or Normal diagnosed patients at the last visit.
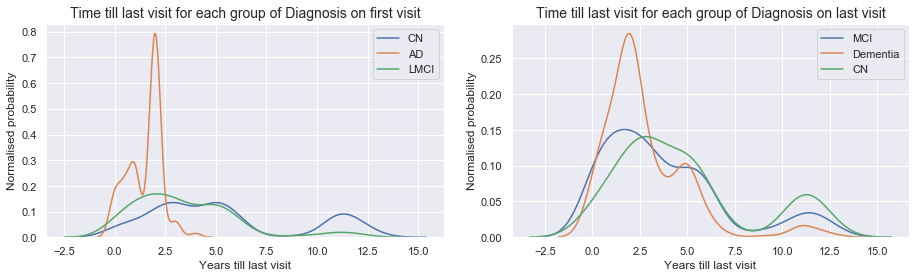
As a second step we remove all the information of the last visit, except the time till the last visit and the diagnosis at the last visit.
- Dropping meaningless and duplicate features
- Keep all features of baseline visit
- Drop all features of the last visit measurements except time till last visit and diagnosis
- Imputation of missing values by 5 KNN
- Scaling between 0 and 1
2 Base Logistic Regression Model
We are splitting in a training set (80%) and test set (20%).
2.1 Basic Naive Logistic model only taking into account time till last visit
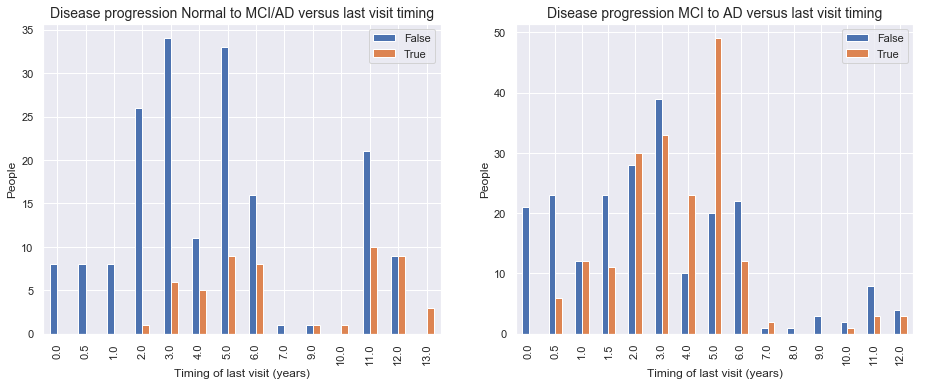
Left graph: Disease progression from normal Baseline to MCI/AD progression on last visit
- We observe more disease progression from normal to MCI or AD when the last visit occurs later. Right graph: Disease progression from MCI at baseline to AD at the last visit
- For MCI to AD disease progression we see no real difference in distribution of people with disease progression and people without disease when we only look at the variable of when the last visit occurs. The time till last visit will be far less important or non-predictive in our predictive model to model change from MCI baseline to AD at last visit.
2.1.1 Logistic Regression Disease progression model for baseline normal patients based only on time till last visit
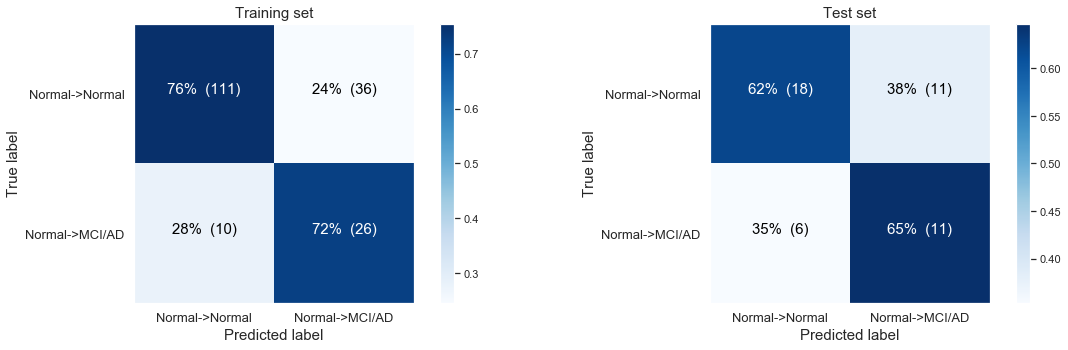
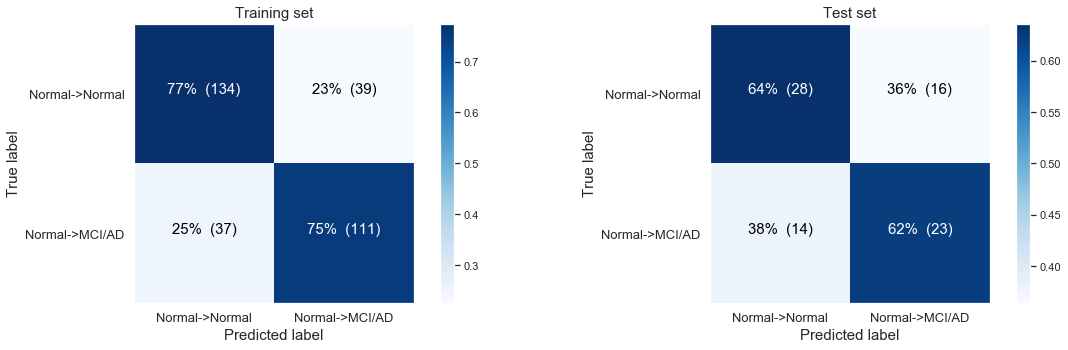
The following confusion matrix: Modeling the disease progression from normal Baseline progressing to MCI/AD at last visit only based on time till last visit.
Simple logistic regression modeling with the CLASS WEIGHTS NON BALANCED
Logistic Regresssion predicting desease progression from Normal Baseline to MCI or AD at last visit.
Training accuracy: 0.80
Test accuracy: 0.63
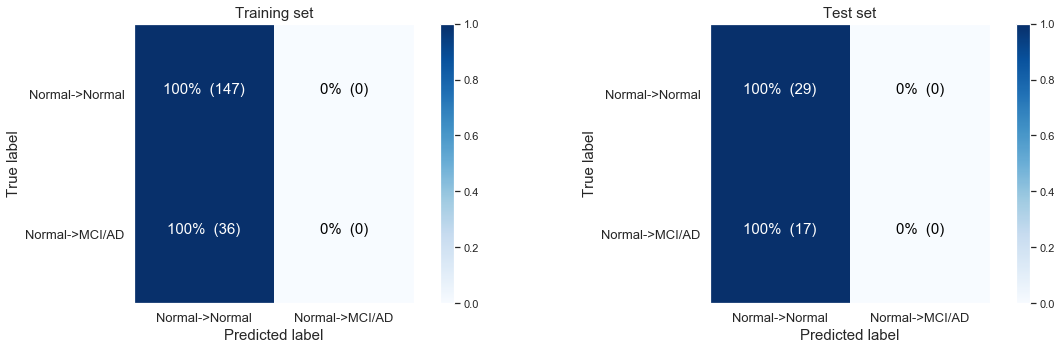
We observe that the model is not predicting anything at all! The most likely case is for people to stay stabile and to show no disease progression at the last visit:
- 147 stabile patients in our training set, 29 in our test set
- 36 with disease progression in our training set, , 17 in our test set.
If we don’t balance for the unequal classes we end up in our very basic logistic regression model always “predicting” a person will stay stabile. Here we are still only using the ‘time till the last visit’ as our single variable.
The following confusion matrix: We get a better model when we balance the unequal size groups (by the parameter class_weight='balanced' in our LogisticRegression() object. Here we see we are now able to predict the people that are showing disease progression, yet of the cost of more false positives and with low discrimitive power.
Simple logistic regression modeling with the CLASS WEIGHTS BALANCED
Logistic Regresssion predicting desease progression from Normal Baseline to MCI or AD at last visit
Training accuracy: 0.70
Test accuracy: 0.70
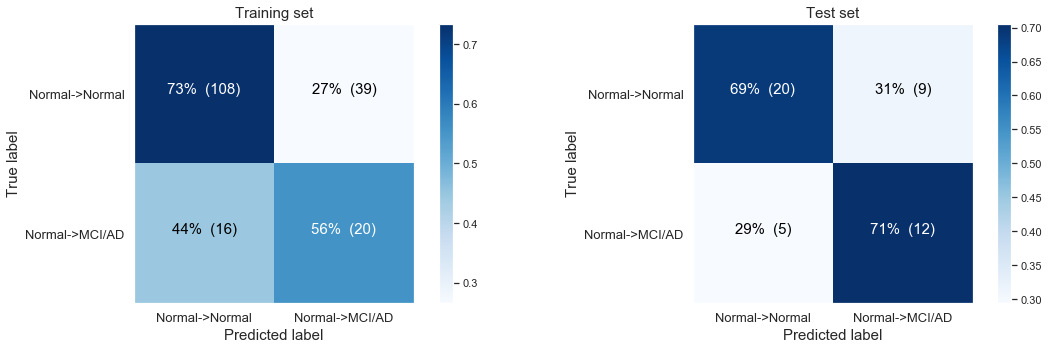
The balancing of the unequal size groups by the parameter class_weight='balanced' did increase our test accuracy from 0.63 to 0.70.
2.1.2 Logistic Regression Disease progression model for baseline MCI patients based only on time till last visit
The following confusion matrix: Modelling non-balanced, MCI Baseline, progressing to AD at last visit only based on time till last visit.
Simple logistic regression modeling with the CLASS WEIGHTS NON BALANCED
Logistic Regresssion predicting desease progression from MCI Baseline to AD at last visit
Training accuracy: 0.58
Test accuracy: 0.49
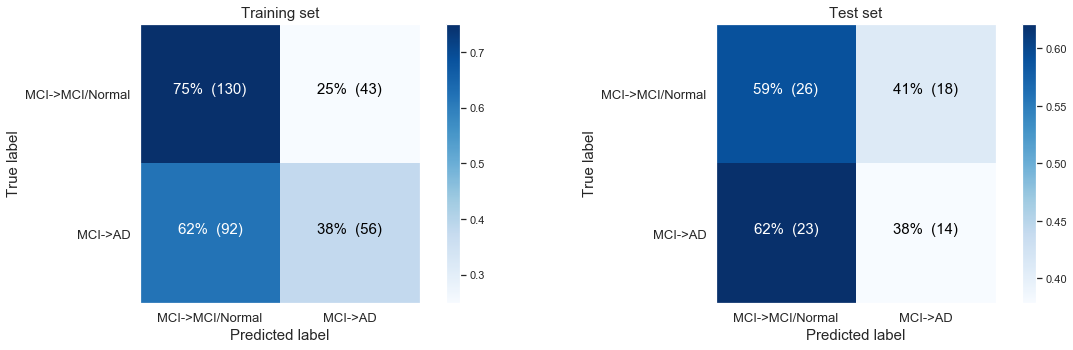
As expected from the first barchart in 2.1.: For MCI to AD disease progression we saw no real difference in distribution of people with disease progression and people without disease when we looked at the variable of when the last visit occurs. The time till last visit will be far less important or non-predictive in our predictive model to model change from MCI baseline to AD at last visit. Here we observe a test accuracy of 0.49, so indeed a very bad performance.
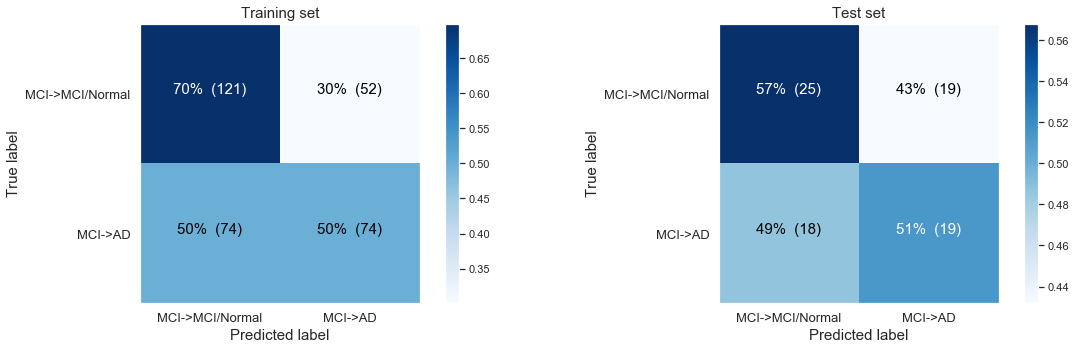
The following confusion matrix: Modelling balanced, MCI Baseline, progressing to AD only based on time till last visit, yet now again with balanced class.
Simple logistic regression modeling with the CLASS WEIGHTS BALANCED
Logistic Regresssion predicting desease progression from MCI Baseline to AD at last visit
Training accuracy: 0.61
Test accuracy: 0.54
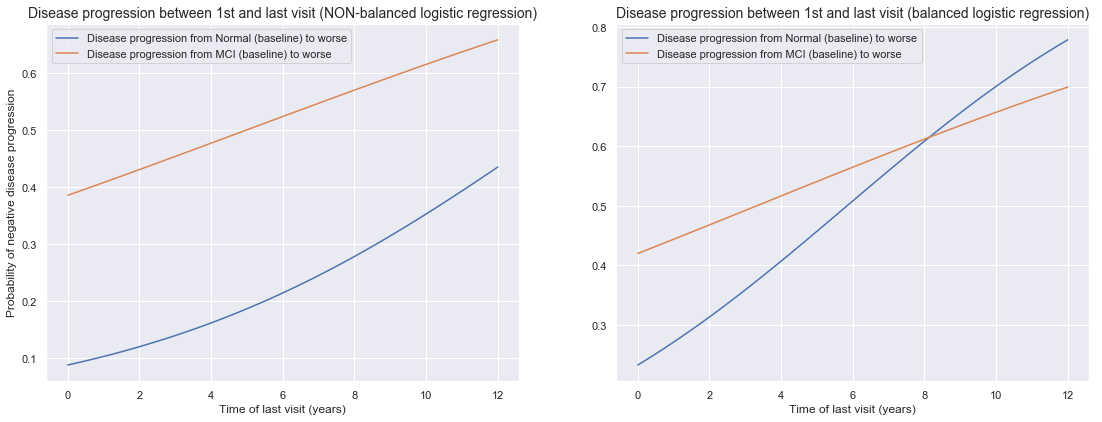
We can plot the logistic regression model by looking at the probabilit of disease progression versus the time of our last visit. Our non-balanced model was not good, yet in our balanced model we observed a big improvement of our normal baseline to MCI/AD progression model. Here we can observe this also by an increased slope for the balanced model for predicting normal baseline to MCI/AD progression model (right graph, blue line).
2.2 Logistic model taking into account all baseline measurements and time till last visit
2.2.1 Modelling Normal Baseline progression to MCI/AD with all baseline features and the time till last visit
Simple logistic regression modeling with the CLASS WEIGHTS BALANCED
Logistic Regresssion predicting desease progression from Normal Baseline to MCI or AD at last visit
Training accuracy: 0.75
Test accuracy: 0.63
Most important features are the ADAS (Alzheimers Disease Assessment Scale) results,
patient education and FAQ_bl (Functinoal Activities Questionnaire score at baseline).
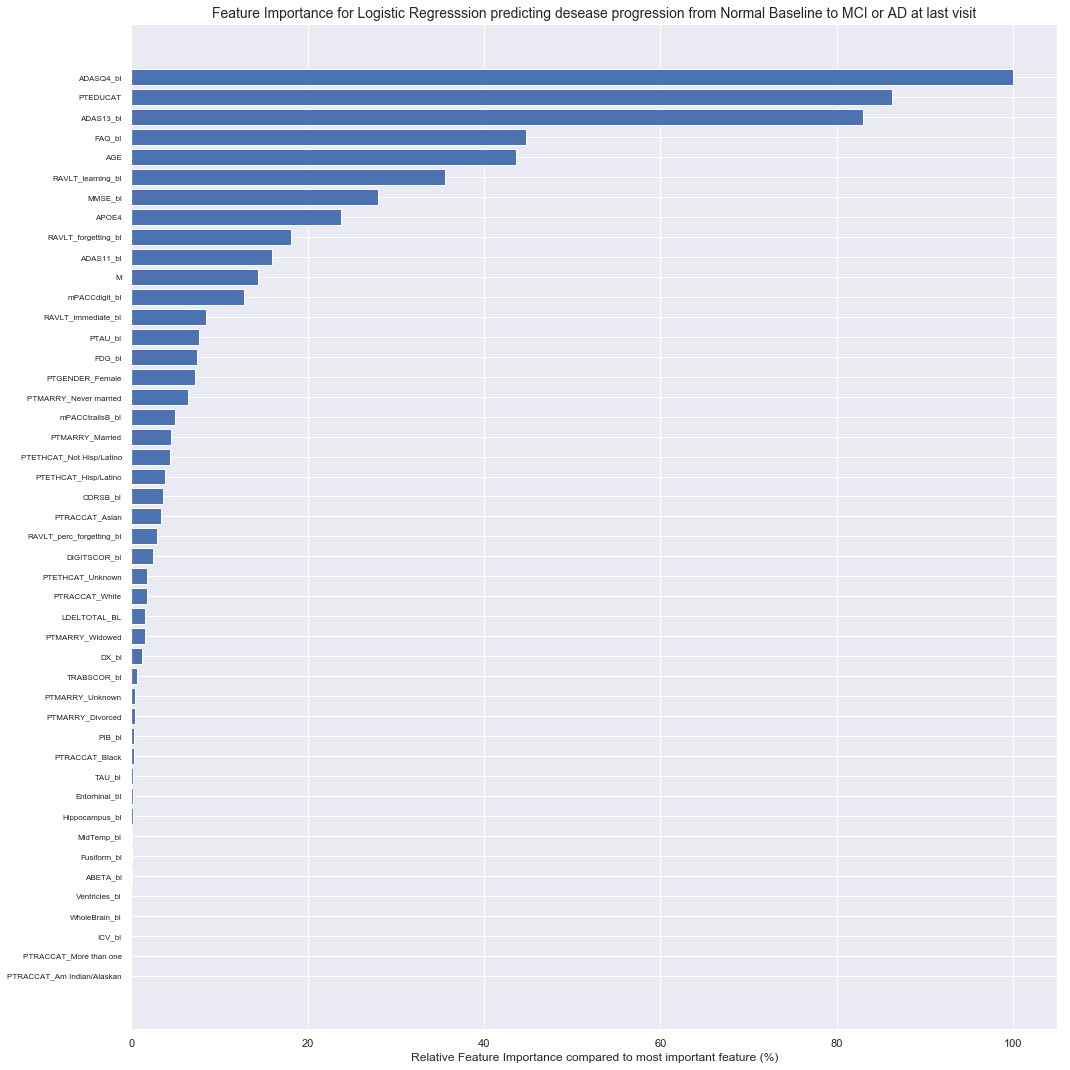
2.2.2 Modelling MCI Baseline progression to AD with all baseline features and the time till last visit
Simple logistic regression modeling with the CLASS WEIGHTS BALANCED
Logistic Regresssion predicting desease progression from Normal Baseline to MCI or AD at last visit
Training accuracy: 0.76 , Test accuracy: 0.63
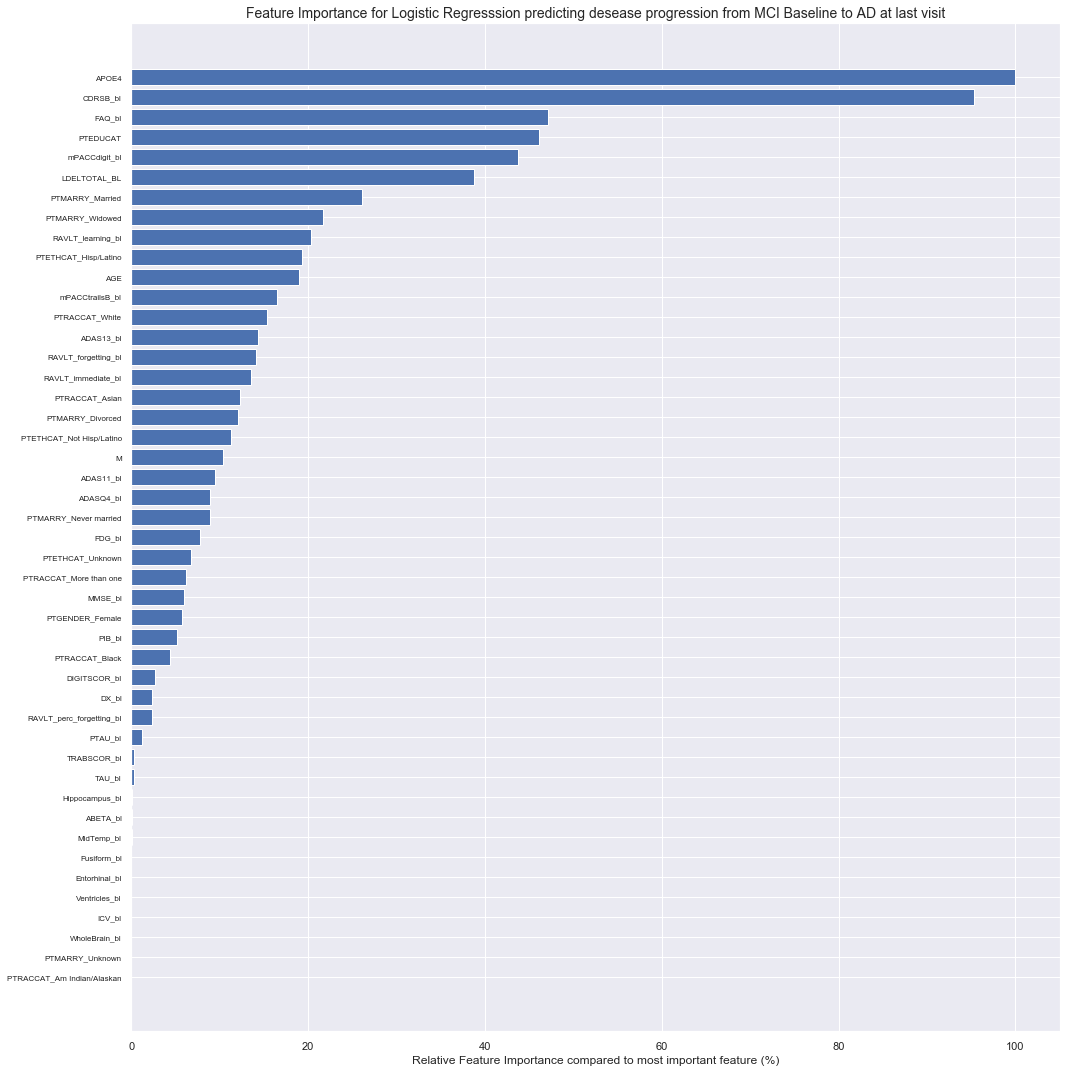
Most important features:
1. M : Months after baseline
2. CDRSB_bl : Clinical Dementia Rating–Sum of Boxes at baseline.
3. FAQ_bl : Functinoal Activities Questionnaire score at baseline
3 Advanced Model Testing with Cross Validation score reporting and CV parameter optimization within training fold
3.1 Parameter Optimisation and Cross Validation
- Parameters were optimised by a grid search on specific parameter values using a 3-fold cross-validation on the 75 percent training cohort to determine which parameter values led to the best performance.
- For quantification of this 3-fold cross-validation (CV) the accuracy was used as the scoring function.
- After this three-fold CV, the best set of parameters was used to train a model on the full 75% training set, and this model was validated on the remaining 25% percent test cohort.
- At the end we present the average and standard deviation of the accuracy, precision, recall, sensitivity, AUROC etc. of these 4 outer Cross Validations.
Cross-validation setting:
- 4-fold cross validation ( so averages on these 4 test sets will be reported )
- Within every training fold of cross validation we do an internal 3-fold CV to optimise the parameters
How do we asses the performance of our models, what is our scoring function?
The performance of machine-learning models, was quantified by 4-fold cross-validation as mentioned before. Each of 4 folds produced a machine learning model trained on 75 percent of the dataset and was validated on the remaining 25 percent of the dataset. This resulted in a final independent validation prediction for every single subject of the cohort based on a independent training set of 75 percent of the dataset not including the specific subject itself.
Two performance measurements were used specifically that allowed us to evaluate the predictions in a threshold independent manner. This is important since this is how we can avoid the problem of having to set a threshold or to balance our initial groups to prevent our model from always predicting the same outcome for all (the outcome of the largest group of our training set).
- Area Under the Receiver Operating Characteristic curve (AUROC) as defined by Scikit-learn’s
roc_auc_score(). - Average Precision-Recall (APR) as defined by Scikit-learn’s
average_precision_score(). Average Precision-Recall summarizes the precision-recall curve as the weighted mean of precisions achieved at each threshold, with the increase in recall from the previous threshold used as the weight [1]. The APR is approximately AUROC multiplied by the initial precision of the system [2]. For each model AUROC and APR was reported as well as the absolute difference with baseline risk prediction (American ACC/AHA ASCDV or European SCORE risk estimation).
[1] Zhu M. Recall, precision and average precision. Working Paper 2004-09, Department of Statistics & Actuarial Science University of Waterloo 2004; :1–11.
[2] Su W, Yuan Y, Zhu M. A Relationship between the Average Precision and the Area Under the ROC Curve. Proceedings of the 2015 International Conference on The Theory of Information Retrieval 2015; :349–52. doi: 10.1145/2808194.2809481
Illustrated example of Parameter Optimization:
Model: LogisticRegression(random_state = 1, solver = 'liblinear', class_weight = 'balanced')
Tested Estimator_parameters à 'C': [0.1, 100]`
Estimator_parameters = {'C':[0.1,1,10,100] }
Estimator=LogisticRegression(random_state=1, solver='liblinear', class_weight='balanced')
Here below we see a print of all the 4 Cross validations, the accuracy scores with also the best set of paremeters in this run. We see that with every CV run we add a value of the outer validation accuaracy to the last list that is printed.
All 4 PARAMETER OPTIMISATIONS AND CROSS VALIDATIONS OF THE "LogisticRegression()" ALGORITHM
This is optimisation and CV number 1 ----------------------------------------------------------------------------
Mean scores: [0.729 0.6981 0.6993 0.6894]
Differences best - other scores: [0. 0.0309 0.0297 0.0396]
The best paremeters set was Set 1: {'C': 0.1}
Validation AUROC score: [0.7]
This is optimisation and CV number 2 ----------------------------------------------------------------------------
Mean scores: [0.6746 0.6453 0.6724 0.6418]
Differences best - other scores: [0. 0.0293 0.0022 0.0328]
The best paremeters set was Set 1: {'C': 0.1}
Validation AUROC score: [0.7 0.8]
This is optimisation and CV number 3 ----------------------------------------------------------------------------
Mean scores: [0.7271 0.7117 0.7052 0.7052]
Differences best - other scores: [0. 0.0154 0.0218 0.0219]
The best paremeters set was Set 1: {'C': 0.1}
Validation AUROC score: [0.7 0.8 0.56]
This is optimisation and CV number 4 ----------------------------------------------------------------------------
Mean scores: [0.6941 0.6677 0.6755 0.6781]
Differences best - other scores: [0. 0.0264 0.0186 0.016 ]
The best paremeters set was Set 1: {'C': 0.1}
Validation AUROC score: [0.7 0.8 0.56 0.8 ]
Elapsed time: 0.83 seconds.
We can summarize the performance of every parameter set by averaging all 4 validation scores. Looking at which set gave us the highest average score indicates the best parameter setting.
Parameter tested: {'C': [0.1, 1, 10, 100]}
Average of 4 splits mean_test_score for all 4 parameter sets:
[0.705 0.6825 0.69 0.68 ]
Differences best Average - Average for all 4 parameter sets:
[0. 0.0225 0.015 0.025 ]
Best Average mean_test_score = 0.7 for the 1th parameter: {'C': 0.1}
Index of the Best Parameter Set for all 4 splits: [1, 1, 1, 1]
Occurences of all 4 parameters as Best Parameter Set in a split:
(Counter(index: times_the_best))) Counter({1: 4})
After the for runs of cross validation and parameter optimization we see that our second parameter $C=0.1$ is performing the best. It has the best mean test score from all the tested values for $C:[0.1,1,10,100]$ that were tested.
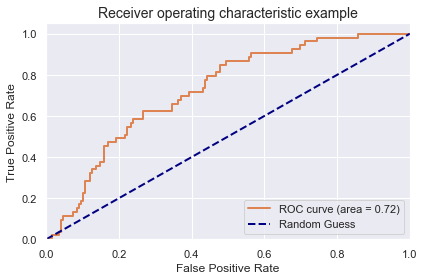
3.2 Model Performance and Area Under The Receiver Operating Characteristic Curve
Estimator : All 4 AUROC Scores of validation on the outer test set with
the estimator with the optimised parameters trained on the inner test set:
[0.70292208 0.8041958 0.56118881 0.7972028 ]
Avg (+- STD )
-----------------
AUROC: 0.716 (+- 0.098)
Accuracy: 0.677 (+- 0.097)
| Logistic_mu | Logistic_std | |
|---|---|---|
| Average Precision | 0.43 | 0.10 |
| AUROC | 0.72 | 0.10 |
| Precision | 0.39 | 0.11 |
| Recall | 0.62 | 0.17 |
| F1_Score | 0.48 | 0.13 |
| Sensitivity | 0.62 | 0.17 |
| Specificity | 0.69 | 0.09 |
| Accuracy | 0.68 | 0.10 |
The actual Parameter Optimisation and 4-fold CV code
def CV_and_Parameter_Optimization(X_CV, y_CV, splits, Estimator, Estimator_parameters):
splits=4
start = time.time()
# All 10 parameter optimisations and cross validations of a certain Classifier
strat_kfold_external = StratifiedKFold(n_splits=splits, shuffle=True, random_state=1)
splitted_indexes_external = strat_kfold_external.split(X_CV, y_CV)
params= [len(Estimator_parameters[param]) for param in Estimator_parameters]
total_params= np.prod(params)
best_index=[]
AP_Score =np.array([])
ROC_Score =np.array([])
Prec_Score =np.array([])
Recall_Score =np.array([])
F1_Score =np.array([])
Sens_Score =np.array([])
Spec_Score =np.array([])
Accuracy_Score =np.array([])
best_predictions_all=np.array([])
test_all=np.array([])
i=1
Sum=[0]*total_params
for train_index_external, test_index_external in splitted_indexes_external:
print("Parameter optimisation and CV number {} ... \t AUROC scores: {}".format(i, ROC_Score .round(3)))
i=i+1
# take i’th fold as test set and the other 3 folds together as training set
X_train, X_test = X_CV.iloc[train_index_external], X_CV.iloc[test_index_external]
y_train, y_test = y_CV.iloc[train_index_external], y_CV.iloc[test_index_external]
# take the training set and split it randomly (stratified)
# in an inner training set of 2/3 size and an inner validation set of 1/3 size
# for each of the ML methods
# for each combination of parameter values
# train the ML method with specified parameters on inner training set and validate on inner validation set
# take the combination of parameter values that yields highest performance (e.g. area under PR curve),
# also write down this parameter value combination train the ML method with best parameter values on
# the (outer) training set and test on the (outer) test set
mod=clone(Estimator)
optimisation_param_AP = GridSearchCV(estimator=mod, param_grid=Estimator_parameters, cv=3, verbose=0, scoring='roc_auc')
optimisation_param_AP.fit(X_train, y_train)
best_index.append(optimisation_param_AP.best_index_+1)
# Building Estimator with best parameters
best= optimisation_param_AP.best_estimator_
best.fit(X_train, y_train)
best_predictions = best.predict_proba(X_test)[:,1]
best_predictions=best_predictions
Average_precision_score=average_precision_score(y_test, best_predictions)
best_predictions_binary = best.predict(X_test)
t=confusion_matrix(y_test, best_predictions_binary)
sensitivity=(t[1][1]/(t[1][0]+t[1][1]))
specificity=(t[0][0]/(t[0][1]+t[0][0]))
AP_Score =np.append(AP_Score , Average_precision_score)
ROC_Score =np.append(ROC_Score , roc_auc_score(y_test, best_predictions))
Prec_Score =np.append(Prec_Score , precision_score(y_test, best_predictions_binary))
Recall_Score =np.append(Recall_Score , recall_score(y_test, best_predictions_binary))
F1_Score =np.append(F1_Score , f1_score(y_test, best_predictions_binary))
Sens_Score =np.append(Sens_Score , sensitivity)
Spec_Score =np.append(Spec_Score , specificity)
Accuracy_Score =np.append(Accuracy_Score , accuracy_score(y_test, best_predictions_binary))
best_predictions_all=np.append(best_predictions_all,best_predictions)
test_all=np.append(test_all,y_test)
Sum=Sum+(optimisation_param_AP.cv_results_['mean_test_score']).round(2)
print('Done! Validation AUROC score: \t\t\t{}'.format(ROC_Score .round(3)))
end = time.time()
total_time=round(end - start,1)
print('Elapsed time: ', total_time,'seconds.' )
print("\nParameter tested: ", Estimator_parameters)
Avg=Sum/splits
#print('Average of {} splits AUROC for all {} parameter sets:\n{}'.format(splits, total_params, Avg.round(4)))
print('Best Average AUROC = {} for the {}th parameter set: {}'.format(round(Avg.max(),4), Avg.argmax()+1, optimisation_param_AP.cv_results_['params'][Avg.argmax()]))
return AP_Score, ROC_Score, Prec_Score, Recall_Score, F1_Score, Sens_Score, Spec_Score, Accuracy_Score, best_predictions_all, test_all, total_time
And its output:
Estimator_parameters = {'C':[0.1, 0.5, 1, 10, 20] }
Estimator=LogisticRegression(random_state=1, solver='liblinear', class_weight='balanced')
LOGI_AP, LOGI_ROC, LOGI_Prec, LOGI_Recall, LOGI_F1, LOGI_Sens, LOGI_Spec, \
LOGI_Accuracy, LOGI_best_predictions_all, LOGI_test_all , LOGI_time \
= CV_and_Parameter_Optimization(X_CV, y_CV, splits, Estimator, Estimator_parameters)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.703]
Parameter optimisation and CV number 3 ... AUROC scores: [0.703 0.804]
Parameter optimisation and CV number 4 ... AUROC scores: [0.703 0.804 0.561]
Done! Validation AUROC score: [0.703 0.804 0.561 0.797]
Elapsed time: 0.8 seconds.
Parameter tested: {'C': [0.1, 0.5, 1, 10, 20]}
Best Average AUROC = 0.705 for the 1th parameter set: {'C': 0.1}
| Logistic_mean | Logistic_std | |
|---|---|---|
| Average Precision | 0.43 | 0.10 |
| AUROC | 0.72 | 0.10 |
| Precision | 0.39 | 0.11 |
| Recall | 0.62 | 0.17 |
| F1_Score | 0.48 | 0.13 |
| Sensitivity | 0.62 | 0.17 |
| Specificity | 0.69 | 0.09 |
| Accuracy | 0.68 | 0.10 |
| Time | 0.80 | 0.00 |
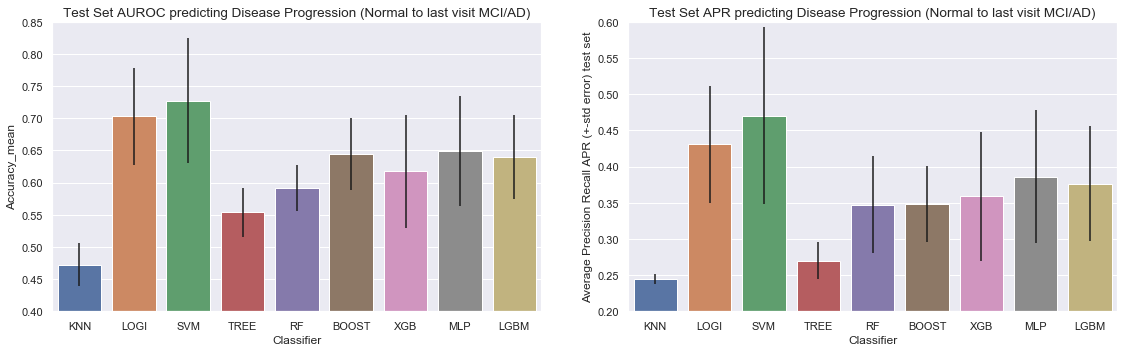
3.4 Model testing of KNN, Logistic Regression, Decision Tree Classifier, Random Forest, Gradient Boosting, XGBoost, MLP and Light-GBM for predicing Normal Baseline patients progressing to MCI/AD at last visit.
3.3.1 KNN: class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto',
leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1, **kwargs)`
Tested parameters:
KNN_parameters = {'p':[1,2],
'n_neighbors':[1, 3, 5, 9]}
KNN = KNeighborsClassifier(weights='distance')
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.492]
Parameter optimisation and CV number 3 ... AUROC scores: [0.492 0.469]
Parameter optimisation and CV number 4 ... AUROC scores: [0.492 0.469 0.509]
Done! Validation AUROC score: [0.492 0.469 0.509 0.42 ]
Elapsed time: 0.6 seconds.
Parameter tested: {'p': [1, 2], 'n_neighbors': [1, 3, 5, 9]}
Best Average AUROC = 0.5725 for the 8th parameter set: {'n_neighbors': 9, 'p': 2}
3.3.2 Logistic Regression: class sklearn.linear_model.LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’liblinear’, max_iter=100, multi_class=’ovr’, verbose=0, warm_start=False, n_jobs=1)
Tested parameters:
LOGI_parameters = {'C':[0.001,0.01,0.1,1,10,100,1000] }
LOGI =LogisticRegression(random_state=1,max_iter=1000,tol=5e-4, solver='liblinear', class_weight='balanced')
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.68]
Parameter optimisation and CV number 3 ... AUROC scores: [0.68 0.78]
Parameter optimisation and CV number 4 ... AUROC scores: [0.68 0.78 0.589]
Done! Validation AUROC score: [0.68 0.78 0.589 0.762]
Elapsed time: 0.5 seconds.
Parameter tested: {'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]}
Best Average AUROC = 0.7175 for the 4th parameter set: {'C': 1}
3.3.3 SVM:class sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
Tested parameters:
SVC_parameters = {'C':[0.00001, 0.0001, 0.001,0.1,1,10,100],
'gamma':[0.0001, 0.001,0.1,1,10,100]}
svc=SVC(probability=True,random_state=1,class_weight='balanced', cache_size=20000,kernel='rbf')
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.661]
Parameter optimisation and CV number 3 ... AUROC scores: [0.661 0.841]
Parameter optimisation and CV number 4 ... AUROC scores: [0.661 0.841 0.605]
Done! Validation AUROC score: [0.661 0.841 0.605 0.802]
Elapsed time: 5.1 seconds.
Parameter tested: {'C': [1e-05, 0.0001, 0.001, 0.1, 1, 10, 100], 'gamma': [0.0001, 0.001, 0.1, 1, 10, 100]}
Best Average AUROC = 0.7425 for the 38th parameter set: {'C': 100, 'gamma': 0.001}
d['3 SVC_mu'] = [SVC_AP.mean(), SVC_ROC.mean(), SVC_Prec.mean(), SVC_Recall.mean(), SVC_F1.mean(), SVC_Sens.mean(), SVC_Spec.mean(), SVC_Accuracy.mean(), SVC_time]
d['3 SVC_std'] = [SVC_AP.std(), SVC_ROC.std(), SVC_Prec.std(), SVC_Recall.std(), SVC_F1.std(), SVC_Sens.std(), SVC_Spec.std(), SVC_Accuracy.std(), 0]
df = pd.DataFrame(data=d, index=Names)
#df[['1 KNN_mu', '2 LOGI_mu', '3 SVC_mu']].round(2)
3.3.4 Decision Tree: class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
Tested parameters:
TREE_parameters ={ 'max_depth':range(2,15,2) }
TREE = DecisionTreeClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.58]
Parameter optimisation and CV number 3 ... AUROC scores: [0.58 0.601]
Parameter optimisation and CV number 4 ... AUROC scores: [0.58 0.601 0.524]
Done! Validation AUROC score: [0.58 0.601 0.524 0.51 ]
Elapsed time: 0.5 seconds.
Parameter tested: {'max_depth': range(2, 15, 2)}
Best Average AUROC = 0.5675 for the 1th parameter set: {'max_depth': 2}
3.3.5 Random Forest: class sklearn.ensemble.RandomForestClassifier(n_estimators=10->100, criterion='gini',
max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None, min_impurity_split=1e-07, bootstrap=True,
oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
Tested parameters:
RF_parameters = {'n_estimators':[50, 100, 500],
'max_features':('sqrt', 'log2'),
'min_samples_leaf':[1, 5]}
RF = RandomForestClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.557]
Parameter optimisation and CV number 3 ... AUROC scores: [0.557 0.645]
Parameter optimisation and CV number 4 ... AUROC scores: [0.557 0.645 0.561]
Done! Validation AUROC score: [0.557 0.645 0.561 0.603]
Elapsed time: 25.4 seconds.
Parameter tested: {'n_estimators': [50, 100, 500], 'max_features': ('sqrt', 'log2'), 'min_samples_leaf': [1, 5]}
Best Average AUROC = 0.625 for the 7th parameter set: {'max_features': 'log2', 'min_samples_leaf': 1, 'n_estimators': 50}
3.3.6 Gradient boosting: class sklearn.ensemble.GradientBoostingClassifier(loss='deviance', learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_depth=3, min_impurity_split=1e-07, init=None, random_state=None, max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, presort='auto')
Tested parameters:
BOOST_parameters = {'n_estimators':[50,100,500],
'max_leaf_nodes':[2,4,8,16],
'learning_rate':[1, 0.5, 0.1, 0.05, 0.01]}
BOOST=GradientBoostingClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.62]
Parameter optimisation and CV number 3 ... AUROC scores: [0.62 0.691]
Parameter optimisation and CV number 4 ... AUROC scores: [0.62 0.691 0.565]
Done! Validation AUROC score: [0.62 0.691 0.565 0.702]
Elapsed time: 74.3 seconds.
Parameter tested: {'n_estimators': [50, 100, 500], 'max_leaf_nodes': [2, 4, 8, 16], 'learning_rate': [1, 0.5, 0.1, 0.05, 0.01]}
Best Average AUROC = 0.665 for the 26th parameter set: {'learning_rate': 0.1, 'max_leaf_nodes': 2, 'n_estimators': 100}
3.3.7. XGBoost: class xgboost.XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True, objective='binary:logistic', booster='gbtree', n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)
Tested parameters:
XGB2_parameters ={ 'max_depth':range(3,10,2),
'min_child_weight':range(1,3,2),
'gamma':[0, 0.1,0.2],
'subsample':[i/10.0 for i in range(6,9,2)],
'colsample_bytree':[i/10.0 for i in range(6,9,2)],
'reg_alpha':[0, 0.005, 0.01, 0.05]}
XGB2 = XGBClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.537]
Parameter optimisation and CV number 3 ... AUROC scores: [0.537 0.766]
Parameter optimisation and CV number 4 ... AUROC scores: [0.537 0.766 0.584]
Done! Validation AUROC score: [0.537 0.766 0.584 0.584]
Elapsed time: 84.1 seconds.
Parameter tested: {'max_depth': range(3, 10, 2), 'min_child_weight': range(1, 3, 2), 'gamma': [0, 0.1, 0.2], 'subsample': [0.6, 0.8], 'colsample_bytree': [0.6, 0.8], 'reg_alpha': [0, 0.005, 0.01, 0.05]}
Best Average AUROC = 0.6425 for the 183th parameter set: {'colsample_bytree': 0.8, 'gamma': 0.2, 'max_depth': 7, 'min_child_weight': 1, 'reg_alpha': 0.05, 'subsample': 0.6}
3.3.8 MLP: class sklearn.neural_network.MLPClassifier(hidden_layer_sizes=(100, ), activation='relu', solver='adam', alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
Tested parameters:
MLP_parameters = {'activation':('relu', 'logistic'),
'hidden_layer_sizes':[(3, ),(20, ),(20,20 ),(50, ),(50,50 ),(100, )],
'alpha':[0.0001,0.001,0.09,0.1,0.5]}
MLP = MLPClassifier(random_state=1, max_iter=500,solver='adam')
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.674]
Parameter optimisation and CV number 3 ... AUROC scores: [0.674 0.561]
Parameter optimisation and CV number 4 ... AUROC scores: [0.674 0.561 0.582]
Done! Validation AUROC score: [0.674 0.561 0.582 0.778]
Elapsed time: 142.2 seconds.
Parameter tested: {'activation': ('relu', 'logistic'), 'hidden_layer_sizes': [(3,), (20,), (20, 20), (50,), (50, 50), (100,)], 'alpha': [0.0001, 0.001, 0.09, 0.1, 0.5]}
Best Average AUROC = 0.73 for the 60th parameter set: {'activation': 'logistic', 'alpha': 0.5, 'hidden_layer_sizes': (100,)}
3.3.9 LGBM: class lightgbm.Dataset(data, label=None, reference=None, weight=None, group=None, init_score=None, silent=False, feature_name='auto', categorical_feature='auto', params=None, free_raw_data=True)
Test parameters:
- max_depth = 2, 3, 4, 5, 6, 7, 8, 9,10, 30
- n_estimators = 5, 25, 50
LGBM_params = {'max_depth' : [2,3,4,5,6,7,8,9,10, 30],
'n_estimators': [5, 25, 50]}
lgbm=LGBMClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.653]
Parameter optimisation and CV number 3 ... AUROC scores: [0.653 0.73 ]
Parameter optimisation and CV number 4 ... AUROC scores: [0.653 0.73 0.545]
Done! Validation AUROC score: [0.653 0.73 0.545 0.632]
Elapsed time: 14.7 seconds.
Parameter tested: {'max_depth': [2, 3, 4, 5, 6, 7, 8, 9, 10, 30], 'n_estimators': [5, 25, 50]}
Best Average AUROC = 0.6475 for the 5th parameter set: {'max_depth': 3, 'n_estimators': 25}
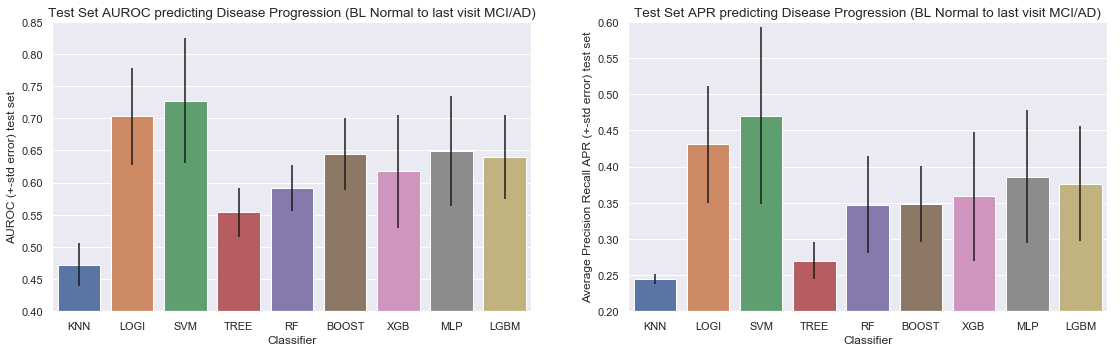
Results for predicting disease progression from Normal baseline to MCI/AD at last visit
| 1 KNN_mu | 2 LOGI_mu | 3 SVC_mu | 4 TREE_mu | 5 RF_mu | 6 BOOST_mu | 7 XGB2_mu | 8 MLP_mu | 9 LGBM_mu | |
|---|---|---|---|---|---|---|---|---|---|
| Average Precision | 0.24 | 0.43 | 0.47 | 0.27 | 0.35 | 0.35 | 0.36 | 0.39 | 0.38 |
| AUROC | 0.47 | 0.70 | 0.73 | 0.55 | 0.59 | 0.64 | 0.62 | 0.65 | 0.64 |
| Precision | 0.03 | 0.36 | 0.44 | 0.29 | 0.08 | 0.11 | 0.40 | 0.36 | 0.14 |
| Recall | 0.02 | 0.64 | 0.61 | 0.26 | 0.02 | 0.05 | 0.09 | 0.27 | 0.07 |
| F1_Score | 0.02 | 0.46 | 0.50 | 0.26 | 0.03 | 0.07 | 0.13 | 0.29 | 0.10 |
| Sensitivity | 0.02 | 0.64 | 0.61 | 0.26 | 0.02 | 0.05 | 0.09 | 0.27 | 0.07 |
| Specificity | 0.94 | 0.66 | 0.75 | 0.77 | 0.97 | 0.93 | 0.91 | 0.90 | 0.94 |
| Accuracy | 0.72 | 0.65 | 0.72 | 0.65 | 0.75 | 0.73 | 0.72 | 0.76 | 0.74 |
| Time | 0.60 | 0.50 | 5.10 | 0.50 | 25.40 | 74.30 | 84.10 | 142.20 | 14.70 |
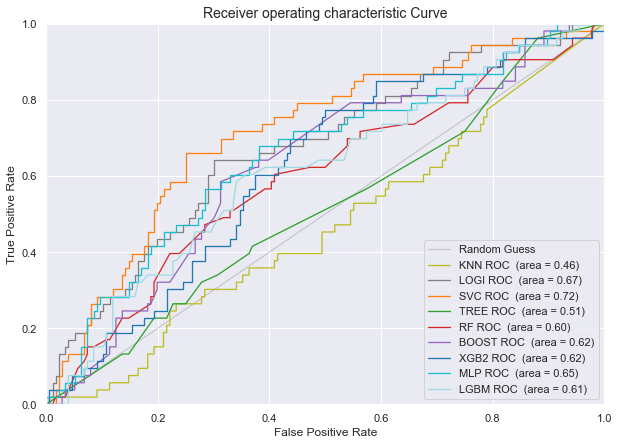
Plot of the AUROC curve for all the classifiers for predicting disease progression from Normal baseline to MCI/AD at last visit
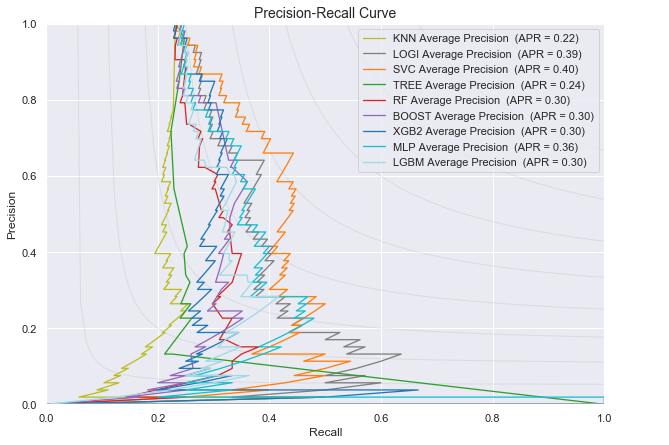
Plot of the Precision-Recall curve for all the classifiers for predicting disease progression from Normal baseline to MCI/AD at last visit
Barchart for all the classifiers for predicting disease progression from Normal baseline to MCI/AD at last visit
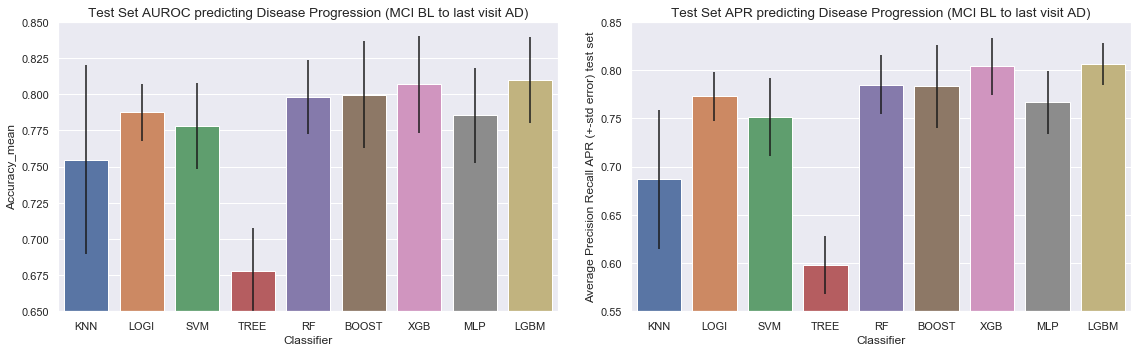
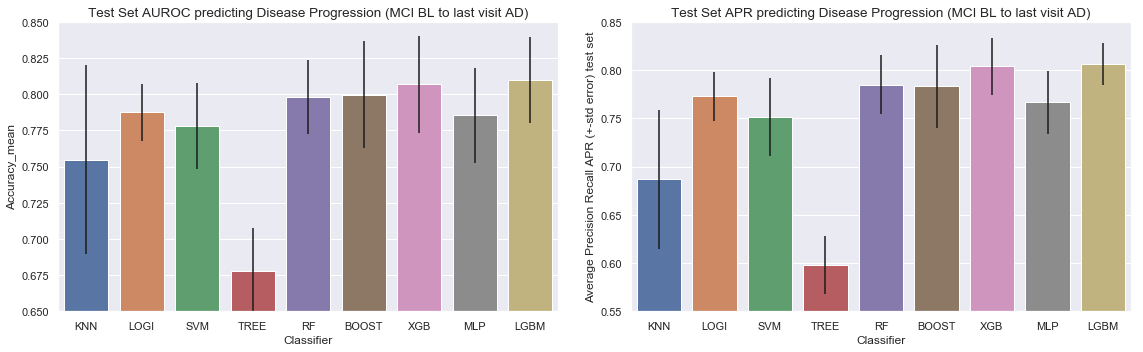
3.4 Model testing of KNN, Logistic Regression, Decision Tree Classifier, Random Forest, Gradient Boosting, XGBoost, MLP and Light-GBM for predicing MCI Baseline patients progressing to AD at last visit.
3.4.1 KNN
KNN_parameters = {'p':[1,2], 'n_neighbors':[1, 3, 5, 9]}
KNN = KNeighborsClassifier(weights='distance')
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.679]
Parameter optimisation and CV number 3 ... AUROC scores: [0.679 0.745]
Parameter optimisation and CV number 4 ... AUROC scores: [0.679 0.745 0.859]
Done! Validation AUROC score: [0.679 0.745 0.859 0.737]
Elapsed time: 0.8 seconds.
Parameter tested: {'p': [1, 2], 'n_neighbors': [1, 3, 5, 9]}
Best Average AUROC = 0.7275 for the 8th parameter set: {'n_neighbors': 9, 'p': 2}
3.4.2 Logistic Regression
LOGI_parameters = {'C':[0.001,0.01,0.1,1,10,100,1000] }
LOGI =LogisticRegression(random_state=1,max_iter=1000,tol=5e-4, solver='liblinear', class_weight='balanced')
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.785]
Parameter optimisation and CV number 3 ... AUROC scores: [0.785 0.772]
Parameter optimisation and CV number 4 ... AUROC scores: [0.785 0.772 0.82 ]
Done! Validation AUROC score: [0.785 0.772 0.82 0.772]
Elapsed time: 0.5 seconds.
Parameter tested: {'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]}
Best Average AUROC = 0.775 for the 4th parameter set: {'C': 1}
3.4.3 SVM
SVC_parameters = {'C':[0.1,1,10],
'gamma':[0.01,0.1,1] }
svc=SVC(probability=True,random_state=1,class_weight='balanced', cache_size=20000,kernel='rbf')
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.766]
Parameter optimisation and CV number 3 ... AUROC scores: [0.766 0.759]
Parameter optimisation and CV number 4 ... AUROC scores: [0.766 0.759 0.83 ]
Done! Validation AUROC score: [0.766 0.759 0.83 0.758]
Elapsed time: 2.3 seconds.
Parameter tested: {'C': [0.1, 1, 10], 'gamma': [0.01, 0.1, 1]}
Best Average AUROC = 0.7725 for the 5th parameter set: {'C': 1, 'gamma': 0.1}
d['3 SVC_mu'] = [SVC_AP.mean(), SVC_ROC.mean(), SVC_Prec.mean(), SVC_Recall.mean(), SVC_F1.mean(), SVC_Sens.mean(), SVC_Spec.mean(), SVC_Accuracy.mean(), SVC_time]
d['3 SVC_std'] = [SVC_AP.std(), SVC_ROC.std(), SVC_Prec.std(), SVC_Recall.std(), SVC_F1.std(), SVC_Sens.std(), SVC_Spec.std(), SVC_Accuracy.std(), 0]
df = pd.DataFrame(data=d, index=Names)
#df[['1 KNN_mu', '2 LOGI_mu', '3 SVC_mu']].round(2)
3.4.4 Decision Tree
TREE_parameters ={ 'max_depth':range(2,15,2) }
TREE = DecisionTreeClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.689]
Parameter optimisation and CV number 3 ... AUROC scores: [0.689 0.719]
Parameter optimisation and CV number 4 ... AUROC scores: [0.689 0.719 0.639]
Done! Validation AUROC score: [0.689 0.719 0.639 0.663]
Elapsed time: 0.5 seconds.
Parameter tested: {'max_depth': range(2, 15, 2)}
Best Average AUROC = 0.645 for the 1th parameter set: {'max_depth': 2}
3.4.5 Random Forest
RF_parameters = {'n_estimators':[50, 100, 500],
'max_features':('sqrt', 'log2'),
'min_samples_leaf':[1, 5]}
RF = RandomForestClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.812]
Parameter optimisation and CV number 3 ... AUROC scores: [0.812 0.778]
Parameter optimisation and CV number 4 ... AUROC scores: [0.812 0.778 0.832]
Done! Validation AUROC score: [0.812 0.778 0.832 0.769]
Elapsed time: 30.5 seconds.
Parameter tested: {'n_estimators': [50, 100, 500], 'max_features': ('sqrt', 'log2'), 'min_samples_leaf': [1, 5]}
Best Average AUROC = 0.78 for the 3th parameter set: {'max_features': 'sqrt', 'min_samples_leaf': 1, 'n_estimators': 500}
3.4.6 Gradient boosting
BOOST_parameters = {'n_estimators':[50,100,500],
'max_leaf_nodes':[2,4,8,16],
'learning_rate':[1, 0.5, 0.1, 0.05, 0.01]}
BOOST=GradientBoostingClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.807]
Parameter optimisation and CV number 3 ... AUROC scores: [0.807 0.754]
Parameter optimisation and CV number 4 ... AUROC scores: [0.807 0.754 0.855]
Done! Validation AUROC score: [0.807 0.754 0.855 0.782]
Elapsed time: 96.0 seconds.
Parameter tested: {'n_estimators': [50, 100, 500], 'max_leaf_nodes': [2, 4, 8, 16], 'learning_rate': [1, 0.5, 0.1, 0.05, 0.01]}
Best Average AUROC = 0.7825 for the 13th parameter set: {'learning_rate': 0.5, 'max_leaf_nodes': 2, 'n_estimators': 50}
3.4.7. XGBoost
XGB2_parameters ={ 'max_depth':range(3,10,2),
'min_child_weight':range(1,3,2),
'gamma':[0, 0.1,0.2],
'subsample':[i/10.0 for i in range(6,9,2)],
'colsample_bytree':[i/10.0 for i in range(6,9,2)],
'reg_alpha':[0, 0.005, 0.01, 0.05]}
XGB2 = XGBClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.815]
Parameter optimisation and CV number 3 ... AUROC scores: [0.815 0.758]
Parameter optimisation and CV number 4 ... AUROC scores: [0.815 0.758 0.852]
Done! Validation AUROC score: [0.815 0.758 0.852 0.802]
Elapsed time: 126.9 seconds.
Parameter tested: {'max_depth': range(3, 10, 2), 'min_child_weight': range(1, 3, 2), 'gamma': [0, 0.1, 0.2], 'subsample': [0.6, 0.8], 'colsample_bytree': [0.6, 0.8], 'reg_alpha': [0, 0.005, 0.01, 0.05]}
Best Average AUROC = 0.7925 for the 135th parameter set: {'colsample_bytree': 0.8, 'gamma': 0.1, 'max_depth': 3, 'min_child_weight': 1, 'reg_alpha': 0.05, 'subsample': 0.6}
3.4.8 MLP
MLP_parameters = {'activation':('relu', 'logistic'),
'hidden_layer_sizes':[(3, ),(20, ),(20,20 ),(50, ),(50,50 ),(100, )],
'alpha':[0.0001,0.001,0.09,0.1,0.5]}
MLP = MLPClassifier(random_state=1, max_iter=500,solver='adam')
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.774]
Parameter optimisation and CV number 3 ... AUROC scores: [0.774 0.752]
Parameter optimisation and CV number 4 ... AUROC scores: [0.774 0.752 0.84 ]
Done! Validation AUROC score: [0.774 0.752 0.84 0.776]
Elapsed time: 136.9 seconds.
Parameter tested: {'activation': ('relu', 'logistic'), 'hidden_layer_sizes': [(3,), (20,), (20, 20), (50,), (50, 50), (100,)], 'alpha': [0.0001, 0.001, 0.09, 0.1, 0.5]}
Best Average AUROC = 0.77 for the 12th parameter set: {'activation': 'relu', 'alpha': 0.001, 'hidden_layer_sizes': (100,)}
3.4.9 LGBM
LGBM_params = { 'max_depth' : [2,3,4,5,6,7,8,9,10, 30],
'n_estimators': [5, 25, 50]}
lgbm=LGBMClassifier(random_state=1)
Parameter optimisation and CV number 1 ... AUROC scores: []
Parameter optimisation and CV number 2 ... AUROC scores: [0.821]
Parameter optimisation and CV number 3 ... AUROC scores: [0.821 0.771]
Parameter optimisation and CV number 4 ... AUROC scores: [0.821 0.771 0.851]
Done! Validation AUROC score: [0.821 0.771 0.851 0.797]
Elapsed time: 19.8 seconds.
Parameter tested: {'max_depth': [2, 3, 4, 5, 6, 7, 8, 9, 10, 30], 'n_estimators': [5, 25, 50]}
Best Average AUROC = 0.785 for the 3th parameter set: {'max_depth': 2, 'n_estimators': 50}
Results for predicting disease progression from MCI baseline to Alzheimers at last visit
| 1 KNN_mu | 2 LOGI_mu | 3 SVC_mu | 4 TREE_mu | 5 RF_mu | 6 BOOST_mu | 7 XGB2_mu | 8 MLP_mu | 9 LGBM_mu | |
|---|---|---|---|---|---|---|---|---|---|
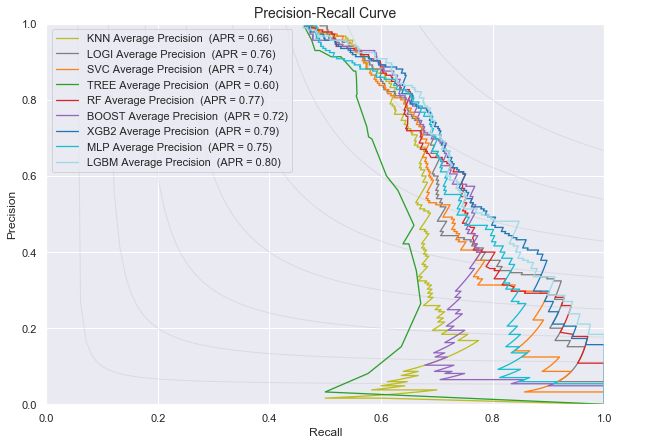
| Average Precision | 0.69 | 0.77 | 0.75 | 0.60 | 0.78 | 0.78 | 0.80 | 0.77 | 0.81 |
| AUROC | 0.75 | 0.79 | 0.78 | 0.68 | 0.80 | 0.80 | 0.81 | 0.79 | 0.81 |
| Precision | 0.65 | 0.68 | 0.67 | 0.62 | 0.70 | 0.71 | 0.72 | 0.70 | 0.71 |
| Recall | 0.75 | 0.72 | 0.72 | 0.59 | 0.65 | 0.69 | 0.68 | 0.69 | 0.71 |
| F1_Score | 0.69 | 0.70 | 0.69 | 0.59 | 0.67 | 0.70 | 0.70 | 0.69 | 0.71 |
| Sensitivity | 0.75 | 0.72 | 0.72 | 0.59 | 0.65 | 0.69 | 0.68 | 0.69 | 0.71 |
| Specificity | 0.64 | 0.70 | 0.70 | 0.69 | 0.75 | 0.75 | 0.76 | 0.75 | 0.75 |
| Accuracy | 0.69 | 0.71 | 0.71 | 0.64 | 0.70 | 0.72 | 0.73 | 0.72 | 0.73 |
| Time | 0.80 | 0.50 | 2.30 | 0.50 | 30.50 | 96.00 | 126.90 | 136.90 | 19.80 |
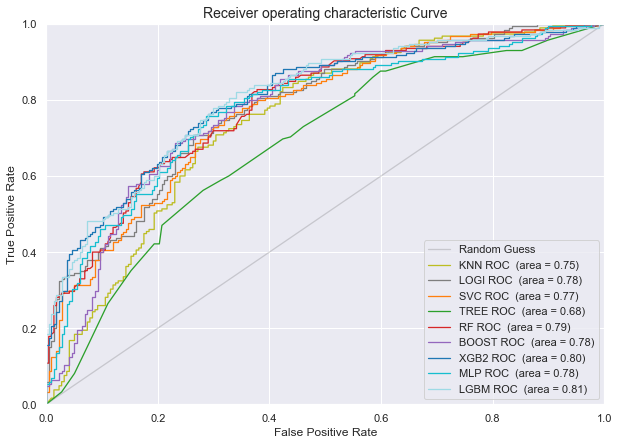
Plot of the AUROC curve for all the classifiers for predicting disease progression from MCI baseline to AD at last visit
Plot of the Precision-Recall curve for all the classifiers for predicting disease progression from MCI baseline to AD at last visit
Barchart for all the classifiers for predicting disease progression from MCI baseline to AD at last visit
4 Summary
Two performance measurements were used specifically that allowed us to evaluate the predictive power of our models in a threshold-independent manner.
Conclusion for the models predicing progression from Normal at Baseline to Mild Cognitive Impairement or Alzheimer at the last visit:
- Area Under the Receiver Operating Curve (AUROC) score: Logistic Regression and Support Vector Machines have by far the highest AUROC score. Although the Support Vector Machine Model showed the highest AUROC we do observe higher variation in results (a higher variation between the different AUROC scores of our 4-Cross Validation folds). The other advanced models (Gradiant Boosting, XGBoost, MLP and LGBM) showed simular performance, but inferior to logistic and SVC.
- Average Precision Recall score: Same observation here, logistic Regression and Support Vector Machines have the highest average precision and recall score.
- Computational Time: Gradient Boosting, XGBoost and MLP are the heaviest computationally. LGBM proved to be very fast compared to the other tree-based models, while still having the same performance. It should be noted that the total time of the parameter optimization depends on the number of tested parameters and all the possible combinations.
| 1 KNN_mu | 2 LOGI_mu | 3 SVC_mu | 4 TREE_mu | 5 RF_mu | 6 BOOST_mu | 7 XGB2_mu | 8 MLP_mu | 9 LGBM_mu | |
|---|---|---|---|---|---|---|---|---|---|
| Average Precision | 0.24 | 0.43 | 0.47 | 0.27 | 0.35 | 0.35 | 0.36 | 0.39 | 0.38 |
| AUROC | 0.47 | 0.70 | 0.73 | 0.55 | 0.59 | 0.64 | 0.62 | 0.65 | 0.64 |
| Precision | 0.03 | 0.36 | 0.44 | 0.29 | 0.08 | 0.11 | 0.40 | 0.36 | 0.14 |
| Recall | 0.02 | 0.64 | 0.61 | 0.26 | 0.02 | 0.05 | 0.09 | 0.27 | 0.07 |
| F1_Score | 0.02 | 0.46 | 0.50 | 0.26 | 0.03 | 0.07 | 0.13 | 0.29 | 0.10 |
| Sensitivity | 0.02 | 0.64 | 0.61 | 0.26 | 0.02 | 0.05 | 0.09 | 0.27 | 0.07 |
| Specificity | 0.94 | 0.66 | 0.75 | 0.77 | 0.97 | 0.93 | 0.91 | 0.90 | 0.94 |
| Accuracy | 0.72 | 0.65 | 0.72 | 0.65 | 0.75 | 0.73 | 0.72 | 0.76 | 0.74 |
| Time | 0.60 | 0.50 | 5.10 | 0.50 | 25.40 | 74.30 | 84.10 | 142.20 | 14.70 |
Conclusion for the models predicting progression from Mild Cognitive Impairement at baseline to Alzheimer at last visit: LGBM and XGBoost have the highest AUROC and Average Precision Recall score, followed by random forest and gradient boosting and logistic regression.
The AUROC in our models for patients evolving from normal to MCI/AD are lower compared to the AUROC for the models predicting which patient will evolve from MCI to AD. This might indicate it is harder to predict who will develop MCI or Alzheimer from normal baseline measurements. Yet once a patient suffers from Mild Cognitive Impairment already, our model can more easily predict if this patient will progress to Alzheimers Disease or not at the last visit. This observation might be explained by the multiple heterogeneous causes that may result in mild cognitive impaired, for example just the process of normal aging in general results in some degree of the loss of memory when people age. Further conclusion are hard to make concrete since we only have 400 individual patients to train our models on.
| 1 KNN_mu | 2 LOGI_mu | 3 SVC_mu | 4 TREE_mu | 5 RF_mu | 6 BOOST_mu | 7 XGB2_mu | 8 MLP_mu | 9 LGBM_mu | |
|---|---|---|---|---|---|---|---|---|---|
| Average Precision | 0.69 | 0.77 | 0.75 | 0.60 | 0.78 | 0.78 | 0.80 | 0.77 | 0.81 |
| AUROC | 0.75 | 0.79 | 0.78 | 0.68 | 0.80 | 0.80 | 0.81 | 0.79 | 0.81 |
| Precision | 0.65 | 0.68 | 0.67 | 0.62 | 0.70 | 0.71 | 0.72 | 0.70 | 0.71 |
| Recall | 0.75 | 0.72 | 0.72 | 0.59 | 0.65 | 0.69 | 0.68 | 0.69 | 0.71 |
| F1_Score | 0.69 | 0.70 | 0.69 | 0.59 | 0.67 | 0.70 | 0.70 | 0.69 | 0.71 |
| Sensitivity | 0.75 | 0.72 | 0.72 | 0.59 | 0.65 | 0.69 | 0.68 | 0.69 | 0.71 |
| Specificity | 0.64 | 0.70 | 0.70 | 0.69 | 0.75 | 0.75 | 0.76 | 0.75 | 0.75 |
| Accuracy | 0.69 | 0.71 | 0.71 | 0.64 | 0.70 | 0.72 | 0.73 | 0.72 | 0.73 |
| Time | 0.80 | 0.50 | 2.30 | 0.50 | 30.50 | 96.00 | 126.90 | 136.90 | 19.80 |